![]()
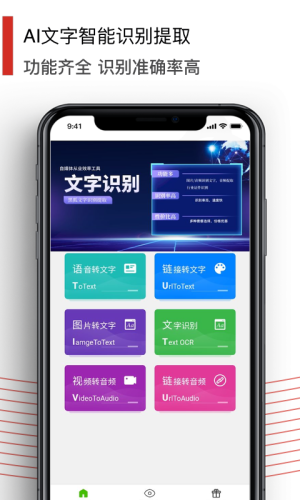
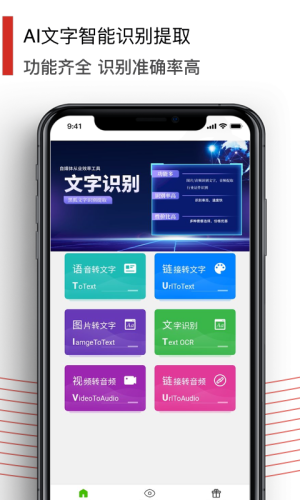
黑狐文字提取识别是一款超级实用的手机文字办公提取工具。有了它,用户可以进行文字的识别和提取。直接导入图片就可以提取图片中的文字了,操作简单,一键轻松提取,让你更好地去工作!

黑狐文字提取识别app是款实用性的手机文字办公提取工具,为各位用户提供了文字的识别和提取,直接导入图片就可以快速提取了,速度快而且准确率高,各位可以放心去使用,完全是免费提供的,为各位整理文件提供更多的便利。
黑狐文字识别提取扫描软件,是一款多功能智能图片文字扫描识别工具。
黑狐文字识别提取ORR神器,提供图片转文字,证件识别扫描,Excel识别,行业文档识别,票据单据识别。
视频提取文字,视频链接转文字,视频转文字,视频转音频,视频链接提取音频下载等多种功能。
强大的文字识别处理技术,可高准确率提取出文字,祝您高效工作的办公效率助手。
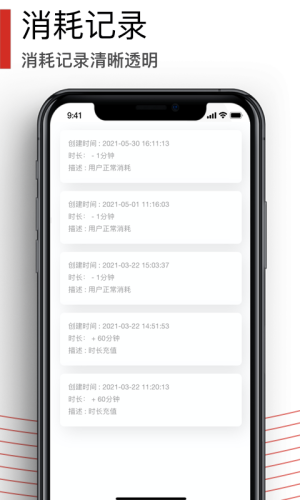
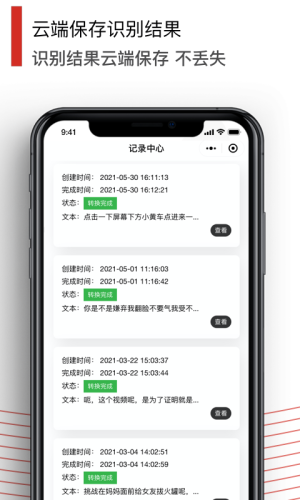
文字提取记录都会保存在云端,供您随时可以查看调阅。
文字扫描识别时间快,识别率高。
1、大家在这里就可以查看各种最新的文字识别工具,只需要拍照就可以快速识别各种工具;
2、在平台里面也可以来复制文字,也可以帮助大家办公更加方便;
3、APP里面的功能也很多,用户们直接就可以识别图片里面的各种文字。
浅谈文字的生成、计算、识别和理解
汉字作为一种最基本的语言计算单位,在自然语言研究和汉语文化推广过程中有其独特的计算逻辑。人们期待未来有一天机器能够像人类一样思考问题、理解语言、生成文本和书写汉字,这就要研究汉字符号及其所表示的文本和语言的认知、学习、生成及理解机理,即不仅要研究文字的可计算性,更要研究语言、词汇和篇章的可计算性。因此,在自然语言处理(NLP)领域,跨专业、跨学科、跨行业的研究势在必行。
文字的生成
文字作为人类用表义符号记录表达信息以传之久远的方式和工具,是文化的主要载体及人类文明的重要标志。从仓颉造字到王选的汉字激光照排系统,人们在不停地寻找能够记录汉字的方法。尤其是进入移动互联网时代以来,关于中文字体自动生成及文本自动生成(又称机器写作)的研究,特别是它们面临的问题与挑战,受到各界的关注。
字体生成目前正从数字化到智能化转型,从而让机器具备像人类一样分析、理解与生成文字形状的能力。2014年,生成式对抗网络(Generative Adversarial Networks,GAN)等深度生成模型的提出推动了图像图形的生成,成为学术界的研究热点。然而,由于字体生成任务对字形质量要求很高,深度生成模型在短时间内还无法满足要求。2016年,北京大学王选计算机研究所团队用偏传统图形学的方法首次解决了大规模手写体中文字库的自动生成问题,并在2017年提出了基于Image2image框架的中文字库生成模型,是学术界最早使用深度生成模型解决中文字体生成任务的工作之一。基于小样本学习的特效字库自动生成模型――AGIS-Net,能够依据极少量输入汉字字形样本,在建模字体风格的同时迁移其纹理特征,解决了基于小样本学习的特效字库自动生成问题。Attribute2Font模型则首次解决了给定任意字体属性值便可自动生成个性化订制风格的完整中英文字库的难题。专业字体设计师开展的实验表明,该系统对他们开展字体设计工作颇有益处。EasyFont模型首次实现了一种基于风格学习的大规模手写体中文字库自动生成系统,使得普通用户快速拥有自己的手写体中文字库的梦想成为可能,目前已通过技术转让方式在企业投入使用。
文本的生成
文本生成,又称自然语言生成(NLG)或者机器写作,是自然语言处理领域的一个重要分支。美联社自2014年7月就开始采用新闻写作软件自动写稿,大大提高了新闻生产效率;新华社、今日头条等也已经将自动写稿机器人投入使用。文本生成的主要方式包括文本扩写、文本缩写、文本改写等。传统的文本生成方法主要基于流水线框架,即“内容选择-文档规划-语句实现”,每个步骤可采用基于模板、规则或统计学习的方法。而端到端的神经网络文本生成模型相对于流水线框架而言更易实现,且能明显提升基于自动评估指标的性能。然而,神经网络文本生成面临生成结果的内容覆盖性不佳、文本多样性不足、信息保真度不够、篇章连贯性不强等挑战。此外,深度生成模型易受对抗攻击,可解释性较差,模型训练的数据依赖性过强。针对文本生成多样性不足的问题,可以通过在解码过程中引入随机性或者进行句法控制与指导等方式提高生成文本的多样性。除了要考虑文本表达上的多样性之外,也可以考虑内容选择上的多样性。
现阶段的机器写作还不能完全代替人类写作,而是与人类写作相互协作。目前的机器写作在素材的依赖性、领域的迁移性以及写作的情感性等方面依然面临很多问题,期待未来机器能够生产出具有丰富情感、充满推理与联想的文章,给人类的生活带来更大的影响。
文字的识别
文字识别旨在将字符图像转化为符号代码,基于篇章的文字识别(即文档分析)是从文档图像提取文本信息,包括文本分割、识别、上下文处理、语义信息提取等。对文本分析的研究从20世纪20年代就已经开始,早期的研究主要集中在单字识别上。对汉字来说,单字识别主要是基于过切分(滑动窗)的识别方法(在此方法中单字识别器的性能起决定作用,切分后会进一步提高汉字的识别精度和结构解释)、基于循环神经网络的文本识别和基于卷积循环神经网络的文本识别。由于汉字数目庞大、大样本学习实现难度较大以及涉及古籍识别等原因,传统的汉字识别策略会遇到很多困难。如果能做到零样本识别,就可以在一定程度上解决这些问题。中科院自动化所研究员刘成林在特邀报告“跨模态零样本文字识别”中指出,零样本识别简单来说就是识别在训练样本中未出现的类别。针对此问题,刘成林介绍了基于部首检测的方法、基于CNN多标记学习的部首检测方法、基于树结构嵌入的方法和基于印刷体原型的手写汉字识别方法等,并指出深度学习为文字识别带来了性能上的突破,零样本文字识别虽然初有成效但识别精度不高,未来的研究方向可以结合多种辅助信息或先验知识进行零样本识别。
文本的理解
“自然语言理解是人工智能皇冠上的明珠”。语言学之于自然语言处理等同于数学之于机器学习,语言学的研究重点是观察、描述、解释自然语言,而NLP的研究重点是语言的可计算性,有了前者才能有后者。虽然语言学是NLP的基础,但是NLP不是语言学的一个分支,也不是语言学的一个扩展。为了让机器能够理解文本和语言,从词汇级、句子级、篇章级三个阶段进行分析具有非常重要的意义。周国栋分析了每个阶段的研究现状,再次强调自然语言理解通常是在篇章级进行,不能断章取义、见微知著。篇章是由一系列连续的语段或句子构成的语言整体单位,在一个有几个子句的篇章实例里,假设有些子句的句法成分缺失,但借助于句子之间的意义关联,就可以构建一个以一个关键词为中心话题的语言整体,从而构成一个篇章。值得注意的是,篇章理解在连贯性、衔接性、跨篇章性和预警性等方面仍面临巨大的挑战。
 下载
识力派OCR文字识别图片转文字
19.0M /
下载
识力派OCR文字识别图片转文字
19.0M /
小编简评:识力派app是
 下载
超能文字识别app
45.3M /
下载
超能文字识别app
45.3M /
小编简评:超能文字识
 下载
照片转文字识别app
8.9M /
下载
照片转文字识别app
8.9M /
小编简评:不限识别次
 下载
文字识别王安卓版
6.3M /
下载
文字识别王安卓版
6.3M /
小编简评:文字识别王
 下载
摄像头文字识别录入
672KB /
下载
摄像头文字识别录入
672KB /
小编简评:摄像头文字
 下载
深度OCR文字识别
5.6M /
下载
深度OCR文字识别
5.6M /
小编简评:深度OCR文字
 下载
元易文字识别app
3.6M /
下载
元易文字识别app
3.6M /
小编简评:元易安卓文
 下载
免费OCR
8.6M /
下载
免费OCR
8.6M /
小编简评:免费OCR是一
 下载
Capture2Text图片文字识别工具
103.5M /
下载
Capture2Text图片文字识别工具
103.5M /
小编简评:Capture2Te
 手机全局复制的软件
手机全局复制的软件
全局复制的手机软件有哪些?小编为大家推荐一些好用的文字提取复制工具,有适用于各种手机信号的软件,也有比较有针对性的APP,不过都是可以正常使用的,大家可以根据自己的手机信号选择对应的全局复制软件,也可以使
 下载
文字提取扫描王app
18.0M /
下载
文字提取扫描王app
18.0M /
小编简评:文字提取扫
 下载
App文字识别翻译
9.6M /
下载
App文字识别翻译
9.6M /
小编简评:文字提取ap
 下载
全局复制xposed版
1.1M /
下载
全局复制xposed版
1.1M /
小编简评:全局复制xp
 下载
安卓全局复制汉化版
1.2M /
下载
安卓全局复制汉化版
1.2M /
小编简评:使用安卓大
 赚点集思吧平台(微赚)
37.3M
4.7.2 官方版
赚点集思吧平台(微赚)
37.3M
4.7.2 官方版
 应用商店(小米自带)app
33.1M
5.4.3 官方版
应用商店(小米自带)app
33.1M
5.4.3 官方版
 自动点击器安卓版
23.7M
2.0.12.24 最新版
自动点击器安卓版
23.7M
2.0.12.24 最新版
 nubia应用中心最新版
15.9M
4.3.0.062814 官方手机版
nubia应用中心最新版
15.9M
4.3.0.062814 官方手机版
 双开助手微分身版
17.6M
10.2.6.0 官方正式版
双开助手微分身版
17.6M
10.2.6.0 官方正式版
 互传vivo一键换机app
44.3M
7.0.8.3 官方最新版
互传vivo一键换机app
44.3M
7.0.8.3 官方最新版
 XY工具库
2.5M
1.0.0 最新版
XY工具库
2.5M
1.0.0 最新版
 乐柠画质助手软件
124.4M
4.8 安卓版
乐柠画质助手软件
124.4M
4.8 安卓版
 play商店安卓版(Google Play 商店)
92.4M
49.3.28-23 最新版
play商店安卓版(Google Play 商店)
92.4M
49.3.28-23 最新版
 葫芦侠最新版本
33.8M
v4.4.1.3 安卓版
葫芦侠最新版本
33.8M
v4.4.1.3 安卓版
 华为应用市场2025最新版
54.9M
15.4.1.300 官方版
华为应用市场2025最新版
54.9M
15.4.1.300 官方版
 冷眸软件库新版
1.3M
10.0 最新版
冷眸软件库新版
1.3M
10.0 最新版



 酷学云教育APP官方版
酷学云教育APP官方版
 瞄准实验室射击辅助手机版
瞄准实验室射击辅助手机版
 点点狼人桌游
点点狼人桌游
 潮汐表预测工具
潮汐表预测工具
 小悟云手机版APP官方版
小悟云手机版APP官方版
 双11任务助手app
双11任务助手app
 情侣飞行棋游戏大全
情侣飞行棋游戏大全
 键鼠映射软件推荐
键鼠映射软件推荐
 社恐app推荐
社恐app推荐
 自动精灵
自动精灵
网友评论