 DNF每日签到送豪
DNF每日签到送豪 lol7月神秘商店
lol7月神秘商店 LOL黑市乱斗怎么
LOL黑市乱斗怎么 LOL英雄成就标志
LOL英雄成就标志相关资讯
本类常用软件
-

福建农村信用社手机银行客户端下载下载量:584204
-

Windows优化大师下载量:416902
-

90美女秀(视频聊天软件)下载量:366961
-

广西农村信用社手机银行客户端下载下载量:365699
-

快播手机版下载量:325855
 骑自行车的正确
骑自行车的正确 在校大学生该如
在校大学生该如 微信朋友圈怎么
微信朋友圈怎么1.背景:
这周由于项目需要对搜索框中输入的错误影片名进行校正处理,以提升搜索命中率和用户体验,研究了一下中文文本自动纠错(专业点讲是校对,proofread),并初步实现了该功能,特此记录。
2.简介:
中文输入错误的校对与更正是指在输入不常见或者错误文字时系统提示文字有误,最简单的例子就是在word里打字时会有红色下划线提示。实现该功能目前主要有两大思路:
(1) 基于大量字典的分词法:主要是将待分析的汉字串与一个很大的“机器词典”中的词条进行匹配,若在词典中找到则匹配成功;该方法易于实现,比较适用于输入的汉字串
属于某个或某几个领域的名词或名称;
(2) 基于统计信息的分词法:常用的是N-Gram语言模型,其实就是N-1阶Markov(马尔科夫)模型;在此简介一下该模型:
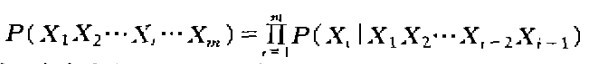
上式是Byes公式,表明字符串X1X2……Xm出现的概率是每个字单独出现的条件概率之积,为了简化计算假设字Xi的出现仅与前面紧挨着的N-1个字符有关,则上面的公式变为:

这就是N-1阶Markov(马尔科夫)模型,计算出概率后与一个阈值对比,若小于该阈值则提示该字符串拼写有误。
3.实现:
由于本人项目针对的输入汉字串基本上是影视剧名称以及综艺动漫节目的名字,语料库的范围相对稳定些,所以这里采用2-Gram即二元语言模型与字典分词相结合的方法;
先说下思路:
对语料库进行分词处理 —> 计算二元词条出现概率(在语料库的样本下,用词条出现的频率代替) —> 对待分析的汉字串分词并找出最大连续字符串和第二大连续字符串 —>
利用最大和第二大连续字符串与语料库的影片名称匹配 —> 部分匹配则现实拼写有误并返回更正的字符串(所以字典很重要)
备注:分词这里用ICTCLAS Java API
上代码:
创建类ChineseWordProofread
3.1 初始化分词包并对影片语料库进行分词处理
1 public ICTCLAS2011 initWordSegmentation(){
2
3 ICTCLAS2011 wordSeg = new ICTCLAS2011();
4 try{
5 String argu = "F:\\Java\\workspace\\wordProofread"; //set your project path
6 System.out.println("ICTCLAS_Init");
7 if (ICTCLAS2011.ICTCLAS_Init(argu.getBytes("GB2312"),0) == false)
8 {
9 System.out.println("Init Fail!");
10 //return null;
11 }
12
13 /*
14 * 设置词性标注集
15 ID 代表词性集
16 1 计算所一级标注集
17 0 计算所二级标注集
18 2 北大二级标注集
19 3 北大一级标注集
20 */
21 wordSeg.ICTCLAS_SetPOSmap(2);
22
23 }catch (Exception ex){
24 System.out.println("words segmentation initialization failed");
25 System.exit(-1);
26 }
27 return wordSeg;
28 }
29
30 public boolean wordSegmentate(String argu1,String argu2){
31 boolean ictclasFileProcess = false;
32 try{
33 //文件分词
34 ictclasFileProcess = wordSeg.ICTCLAS_FileProcess(argu1.getBytes("GB2312"), argu2.getBytes("GB2312"), 0);
35
36 //ICTCLAS2011.ICTCLAS_Exit();
37
38 }catch (Exception ex){
39 System.out.println("file process segmentation failed");
40 System.exit(-1);
41 }
42 return ictclasFileProcess;
43 }3.2 计算词条(tokens)出现的频率
1 public Map<String,Integer> calculateTokenCount(String afterWordSegFile){
2 Map<String,Integer> wordCountMap = new HashMap<String,Integer>();
3 File movieInfoFile = new File(afterWordSegFile);
4 BufferedReader movieBR = null;
5 try {
6 movieBR = new BufferedReader(new FileReader(movieInfoFile));
7 } catch (FileNotFoundException e) {
8 System.out.println("movie_result.txt file not found");
9 e.printStackTrace();
10 }
11
12 String wordsline = null;
13 try {
14 while ((wordsline=movieBR.readLine()) != null){
15 String[] words = wordsline.trim().split(" ");
16 for (int i=0;i<words.length;i++){
17 int wordCount = wordCountMap.get(words[i])==null ? 0:wordCountMap.get(words[i]);
18 wordCountMap.put(words[i], wordCount+1);
19 totalTokensCount += 1;
20
21 if (words.length > 1 && i < words.length-1){
22 StringBuffer wordStrBuf = new StringBuffer();
23 wordStrBuf.append(words[i]).append(words[i+1]);
24 int wordStrCount = wordCountMap.get(wordStrBuf.toString())==null ? 0:wordCountMap.get(wordStrBuf.toString());
25 wordCountMap.put(wordStrBuf.toString(), wordStrCount+1);
26 totalTokensCount += 1;
27 }
28
29 }
30 }
31 } catch (IOException e) {
32 System.out.println("read movie_result.txt file failed");
33 e.printStackTrace();
34 }
35
36 return wordCountMap;
37 }3.3 找出待分析字符串中的正确tokens
1 public Map<String,Integer> calculateTokenCount(String afterWordSegFile){
2 Map<String,Integer> wordCountMap = new HashMap<String,Integer>();
3 File movieInfoFile = new File(afterWordSegFile);
4 BufferedReader movieBR = null;
5 try {
6 movieBR = new BufferedReader(new FileReader(movieInfoFile));
7 } catch (FileNotFoundException e) {
8 System.out.println("movie_result.txt file not found");
9 e.printStackTrace();
10 }
11
12 String wordsline = null;
13 try {
14 while ((wordsline=movieBR.readLine()) != null){
15 String[] words = wordsline.trim().split(" ");
16 for (int i=0;i<words.length;i++){
17 int wordCount = wordCountMap.get(words[i])==null ? 0:wordCountMap.get(words[i]);
18 wordCountMap.put(words[i], wordCount+1);
19 totalTokensCount += 1;
20
21 if (words.length > 1 && i < words.length-1){
22 StringBuffer wordStrBuf = new StringBuffer();
23 wordStrBuf.append(words[i]).append(words[i+1]);
24 int wordStrCount = wordCountMap.get(wordStrBuf.toString())==null ? 0:wordCountMap.get(wordStrBuf.toString());
25 wordCountMap.put(wordStrBuf.toString(), wordStrCount+1);
26 totalTokensCount += 1;
27 }
28
29 }
30 }
31 } catch (IOException e) {
32 System.out.println("read movie_result.txt file failed");
33 e.printStackTrace();
34 }
35
36 return wordCountMap;
37 }
3.4 得到最大连续和第二大连续字符串(也可能为单个字符)
1 public String[] getMaxAndSecondMaxSequnce(String[] sInputResult){
2 List<String> correctTokens = getCorrectTokens(sInputResult);
3 //TODO
4 System.out.println(correctTokens);
5 String[] maxAndSecondMaxSeq = new String[2];
6 if (correctTokens.size() == 0) return null;
7 else if (correctTokens.size() == 1){
8 maxAndSecondMaxSeq[0]=correctTokens.get(0);
9 maxAndSecondMaxSeq[1]=correctTokens.get(0);
10 return maxAndSecondMaxSeq;
11 }
12
13 String maxSequence = correctTokens.get(0);
14 String maxSequence2 = correctTokens.get(correctTokens.size()-1);
15 String littleword = "";
16 for (int i=1;i<correctTokens.size();i++){
17 //System.out.println(correctTokens);
18 if (correctTokens.get(i).length() > maxSequence.length()){
19 maxSequence = correctTokens.get(i);
20 } else if (correctTokens.get(i).length() == maxSequence.length()){
21
22 //select the word with greater probability for single-word
23 if (correctTokens.get(i).length()==1){
24 if (probBetweenTowTokens(correctTokens.get(i)) > probBetweenTowTokens(maxSequence)) {
25 maxSequence2 = correctTokens.get(i);
26 }
27 }
28 //select words with smaller probability for multi-word, because the smaller has more self information
29 else if (correctTokens.get(i).length()>1){
30 if (probBetweenTowTokens(correctTokens.get(i)) <= probBetweenTowTokens(maxSequence)) {
31 maxSequence2 = correctTokens.get(i);
32 }
33 }
34
35 } else if (correctTokens.get(i).length() > maxSequence2.length()){
36 maxSequence2 = correctTokens.get(i);
37 } else if (correctTokens.get(i).length() == maxSequence2.length()){
38 if (probBetweenTowTokens(correctTokens.get(i)) > probBetweenTowTokens(maxSequence2)){
39 maxSequence2 = correctTokens.get(i);
40 }
41 }
42 }
43 //TODO
44 System.out.println(maxSequence+" : "+maxSequence2);
45 //delete the sub-word from a string
46 if (maxSequence2.length() == maxSequence.length()){
47 int maxseqvaluableTokens = maxSequence.length();
48 int maxseq2valuableTokens = maxSequence2.length();
49 float min_truncate_prob_a = 0 ;
50 float min_truncate_prob_b = 0;
51 String aword = "";
52 String bword = "";
53 for (int i=0;i<correctTokens.size();i++){
54 float tokenprob = probBetweenTowTokens(correctTokens.get(i));
55 if ((!maxSequence.equals(correctTokens.get(i))) && maxSequence.contains(correctTokens.get(i))){
56 if ( tokenprob >= min_truncate_prob_a){
57 min_truncate_prob_a = tokenprob ;
58 aword = correctTokens.get(i);
59 }
60 }
61 else if ((!maxSequence2.equals(correctTokens.get(i))) && maxSequence2.contains(correctTokens.get(i))){
62 if (tokenprob >= min_truncate_prob_b){
63 min_truncate_prob_b = tokenprob;
64 bword = correctTokens.get(i);
65 }
66 }
67 }
68 //TODO
69 System.out.println(aword+" VS "+bword);
70 System.out.println(min_truncate_prob_a+" VS "+min_truncate_prob_b);
71 if (aword.length()>0 && min_truncate_prob_a < min_truncate_prob_b){
72 maxseqvaluableTokens -= 1 ;
73 littleword = maxSequence.replace(aword,"");
74 }else {
75 maxseq2valuableTokens -= 1 ;
76 String temp = maxSequence2;
77 if (maxSequence.contains(temp.replace(bword, ""))){
78 littleword = maxSequence2;
79 }
80 else littleword = maxSequence2.replace(bword,"");
81
82 }
83
84 if (maxseqvaluableTokens < maxseq2valuableTokens){
85 maxSequence = maxSequence2;
86 maxSequence2 = littleword;
87 }else {
88 maxSequence2 = littleword;
89 }
90
91 }
92 maxAndSecondMaxSeq[0] = maxSequence;
93 maxAndSecondMaxSeq[1] = maxSequence2;
94
95 return maxAndSecondMaxSeq ;
96 }3.5 返回更正列表
1 public List<String> proofreadAndSuggest(String sInput){
2 //List<String> correctTokens = new ArrayList<String>();
3 List<String> correctedList = new ArrayList<String>();
4 List<String> crtTempList = new ArrayList<String>();
5
6 //TODO
7 Calendar startProcess = Calendar.getInstance();
8 char[] str2char = sInput.toCharArray();
9 String[] sInputResult = new String[str2char.length];//cwp.wordSegmentate(sInput);
10 for (int t=0;t<str2char.length;t++){
11 sInputResult[t] = String.valueOf(str2char[t]);
12 }
13 //String[] sInputResult = cwp.wordSegmentate(sInput);
14 //System.out.println(sInputResult);
15 //float re = probBetweenTowTokens("非","诚");
16 String[] MaxAndSecondMaxSequnce = getMaxAndSecondMaxSequnce(sInputResult);
17
18 // display errors and suggest correct movie name
19 //System.out.println("hasError="+hasError);
20 if (hasError !=0){
21 if (MaxAndSecondMaxSequnce.length>1){
22 String maxSequence = MaxAndSecondMaxSequnce[0];
23 String maxSequence2 = MaxAndSecondMaxSequnce[1];
24 for (int j=0;j<movieName.size();j++){
25 //boolean isThisMovie = false;
26 String movie = movieName.get(j);
27
28
29 //System.out.println("maxseq is "+maxSequence+", maxseq2 is "+maxSequence2);
30
31 //select movie
32 if (maxSequence2.equals("")){
33 if (movie.contains(maxSequence)) correctedList.add(movie);
34 }
35 else {
36 if (movie.contains(maxSequence) && movie.contains(maxSequence2)){
37 //correctedList.clear();
38 crtTempList.add(movie);
39 //correctedList.add(movie);
40 //break;
41 }
42 //else if (movie.contains(maxSequence) || movie.contains(maxSequence2)) correctedList.add(movie);
43 else if (movie.contains(maxSequence)) correctedList.add(movie);
44 }
45
46 }
47
48 if (crtTempList.size()>0){
49 correctedList.clear();
50 correctedList.addAll(crtTempList);
51 }
52
53 //TODO
54 if (hasError ==1) System.out.println("No spellig error,Sorry for having no this movie,do you want to get :"+correctedList.toString()+" ?");
55 //TODO
56 else System.out.println("Spellig error,do you want to get :"+correctedList.toString()+" ?");
57 } //TODO
58 else System.out.println("there are spellig errors, no anyone correct token in your spelled words,so I can't guess what you want, please check it again");
59
60 } //TODO
61 else System.out.println("No spelling error");
62
63 //TODO
64 Calendar endProcess = Calendar.getInstance();
65 long elapsetime = (endProcess.getTimeInMillis()-startProcess.getTimeInMillis()) ;
66 System.out.println("process work elapsed "+elapsetime+" ms");
67 ICTCLAS2011.ICTCLAS_Exit();
68
69 return correctedList ;
70 }3.6 显示校对结果
1 public static void main(String[] args) {
2
3 String argu1 = "movie.txt"; //movies name file
4 String argu2 = "movie_result.txt"; //words after segmenting name of all movies
5
6 SimpleDateFormat sdf=new SimpleDateFormat("HH:mm:ss");
7 String startInitTime = sdf.format(new java.util.Date());
8 System.out.println(startInitTime+" ---start initializing work---");
9 ChineseWordProofread cwp = new ChineseWordProofread(argu1,argu2);
10
11 String endInitTime = sdf.format(new java.util.Date());
12 System.out.println(endInitTime+" ---end initializing work---");
13
14 Scanner scanner = new Scanner(System.in);
15 while(true){
16 System.out.print("请输入影片名:");
17
18 String input = scanner.next();
19
20 if (input.equals("EXIT")) break;
21
22 cwp.proofreadAndSuggest(input);
23
24 }
25 scanner.close();
26 }在我的机器上实验结果如下:
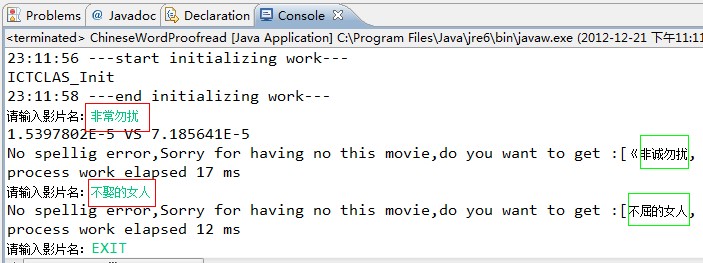
最后要说的是我用的语料库没有做太多处理,所以最后出来的有很多正确的结果,比如非诚勿扰会有《非诚勿扰十二月合集》等,这些只要在影片语料库上处理下即可;
还有就是该模型不适合大规模在线数据,比如说搜索引擎中的自动校正或者叫智能提示,即使在影视剧、动漫、综艺等影片的自动检测错误和更正上本模型还有很多提升的地方,若您不吝惜键盘,请敲上你的想法,让我知道,让我们开源、开放、开心,最后源码在github上,可以自己点击ZIP下载后解压,在eclipse中创建工程wordproofread并将解压出来的所有文件copy到该工程下,即可运行。